Updated CI/CD for KiCad 9 and Gitlab

Introduction
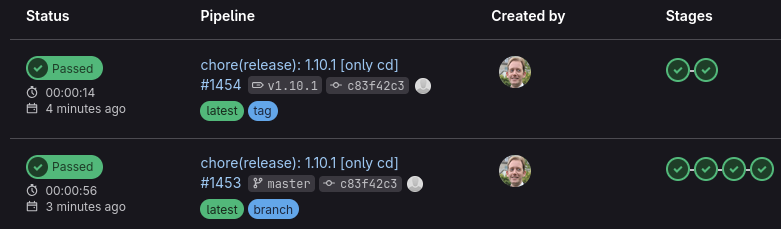
Here are some updates I have made since my original post about using KiCad with CI/CD. It is now using a kicad 9 docker image (ghcr.io/inti-cmnb/kicad9_auto:latest) and runs on the latest gitlab.
Auto adding date and version to PCB/Schematic

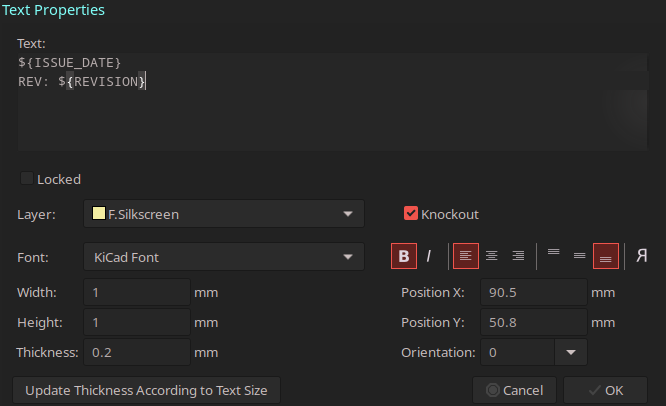
I have added a small change to my CI file to replace the Revision and Date in the Schematic and PCB. This way I will always know exactly which version I ordered at the FAB, as it’s auto-tagged in GitLab and printed on the PCB.
...
# exports the Version and Date into variables
- export VERSION=`cat VERSION.txt` && echo ${VERSION}
- export CURRENT_DATE=`date +'%Y-%m-%d'` && echo ${CURRENT_DATE}
# simple sed replace in the schematic and PCB files
- sed -i "s/\t(rev \"[^\"]*\")/\t(rev \"${VERSION}\")/g" *.kicad_pcb
- sed -i "s/\t(rev \"[^\"]*\")/\t(rev \"${VERSION}\")/g" *.kicad_sch
- sed -i "s/\t(date \"[^\"]*\")/\t(date \"${CURRENT_DATE}\")/g" *.kicad_pcb
- sed -i "s/\t(date \"[^\"]*\")/\t(date \"${CURRENT_DATE}\")/g" *.kicad_sch
# after this I run kibot to generate all the outputs
...
# also add schematic and PCB to the artifacts
# and in the .releaserc.yml so they get commited
artifacts:
when: always
paths:
- Fabrication/
- "*.kicad_pcb"
- "*.kicad_sch"
...In Kicad I use the page variables in the text field.
Added LCSC part numbers to iBom
To make human pick and placing easier, I have added the LCSC part numbers to my iBom. This only required a small change to the configuration.
preflight:
update_xml: true # needed to get the LCSC field
outputs:
- name: ibom
comment: Interactive BOM
type: ibom
dir: Fabrication/ibom
options:
dark_mode: true
name_format: "index"
extra_fields: 'LCSC' # extra field
checkboxes: 'Placed' # I only want the placed checkboxAuto generating BOM labels
I usually order the BOM with the PCB, and I then have a box full of SMD components for a specific project. To make this easier to use than having to go through each bag every time I want to place a component, I have started to print these SMD tape holders. They are small and make it easier to remove the tape.

I used to manually import a CSV of the part numbers and then print those out, but I figured I might as well just write a small script to do this. Sadly, kibot can’t print custom templates, It is possible now to do this directly with kibot (Thank you @set-soft)
Using the current dev image of kibot (ghcr.io/inti-cmnb/kicad9_auto:dev) you can generate the labels directly via:
output.kibot.yaml
- name: basic_bom_labels
comment: BoM labels
type: bom_labels
dir: Fabrication/Labels
options:
bom: bom_labels
- name: bom_labels
comment: BoM to Print Labels
type: bom
run_by_default: false
dir: Fabrication/Labels
options:
format: CSV
output: bom_labels.%x
group_fields:
- LCSC
sort_style: ref
columns:
- LCSC
- Value
- Footprint
csv:
hide_pcb_info: true
hide_stats_info: trueAlternatively a simple Python script can manage it as well. You do have to install a Python library which is not included by default in the ghcr.io/inti-cmnb/kicad9_auto:latest image.
I first generate a CSV of the data I need in kibot:
output.kibot.yaml
- name: bom_labels
comment: "Print Labels"
type: bom
dir: Fabrication/Labels
options:
format: KICAD
group_fields: ['LCSC']
sort_style: ref
columns:
- field: LCSC
name: Part
- field: Value
- field: FootprintI then trigger the script in my pipeline:
.gitlab-ci.yml
- apt-get update -y && apt-get install -y python3-reportlab
- python3 configs/gen-labels.py 'Fabrication/Labels/*.csv'The result is a PDF with one label per page. I can then send this to my cheap label printer HZ-D108B (via my phone; Linux support is garbage) and print off the 20mm x 10mm labels. They fit perfectly on the 3D printed part or one of these SMD storage boxes.
Multi-PCB per project support
My old CI script did not support multiple PCBs in the same project. I have fixed this now.
Full configurations
.gitlab-ci.yml
stages:
- fetch-version
- testing
- gen_fab
- publish
- deploy
variables:
KICAD9_3DMODEL_DIR: "$CI_PROJECT_DIR/packages3d"
KICAD_USER_TEMPLATE_DIR: "$CI_PROJECT_DIR/templates"
# https://levelup.gitconnected.com/semantic-versioning-and-release-automation-on-gitlab-9ba16af0c21
fetch-semantic-version:
image: node:24
stage: fetch-version
only:
refs:
- master
- alpha
- /^(([0-9]+)\.)?([0-9]+)\.x/ # This matches maintenance branches
- /^([0-9]+)\.([0-9]+)\.([0-9]+)(?:-([0-9A-Za-z-]+(?:\.[0-9A-Za-z-]+)*))?(?:\+[0-9A-Za-z-]+)?$/ # This matches pre-releases
script:
- npm install @semantic-release/gitlab @semantic-release/exec @semantic-release/changelog @semantic-release/git -D
- npx semantic-release --generate-notes false --dry-run
artifacts:
paths:
- VERSION.txt
tags:
- docker
generate-non-semantic-version:
stage: fetch-version
except:
refs:
- master
- alpha
- /^(([0-9]+)\.)?([0-9]+)\.x/ # This matches maintenance branches
- /^([0-9]+)\.([0-9]+)\.([0-9]+)(?:-([0-9A-Za-z-]+(?:\.[0-9A-Za-z-]+)*))?(?:\+[0-9A-Za-z-]+)?$/ # This matches pre-releases
script:
- echo build-$CI_PIPELINE_ID > VERSION.txt
artifacts:
paths:
- VERSION.txt
tags:
- docker
tests:
image: ghcr.io/inti-cmnb/kicad9_auto:latest
stage: testing
script:
- pwd
- |
for pcb in *.kicad_pcb; do
if [[ -f "$pcb" ]]; then
echo "Testing PCB: $pcb"
# Get the base name without extension
base_name="${pcb%.kicad_pcb}"
sch_file="${base_name}.kicad_sch"
if [[ -f "$sch_file" ]]; then
echo " Found matching schematic: $sch_file"
# Both files exist, use project mode
kibot -c test.kibot.yaml -e "$pcb"
else
echo " No schematic found, using --no-check-sch"
# No schematic, skip the check
kibot -c test.kibot.yaml -e "$pcb" --no-check-sch
fi
fi
done
tags:
- docker
pcb_outputs:
image: ghcr.io/inti-cmnb/kicad9_auto:latest
stage: gen_fab
script:
- export VERSION=`cat VERSION.txt` && echo ${VERSION}
- export CURRENT_DATE=`date +'%Y-%m-%d'` && echo ${CURRENT_DATE}
- sed -i "s/\t(rev \"[^\"]*\")/\t(rev \"${VERSION}\")/g" *.kicad_pcb
- sed -i "s/\t(rev \"[^\"]*\")/\t(rev \"${VERSION}\")/g" *.kicad_sch
- sed -i "s/\t(date \"[^\"]*\")/\t(date \"${CURRENT_DATE}\")/g" *.kicad_pcb
- sed -i "s/\t(date \"[^\"]*\")/\t(date \"${CURRENT_DATE}\")/g" *.kicad_sch
- |
for pcb in *.kicad_pcb; do
if [[ -f "$pcb" ]]; then
echo "Processing PCB: $pcb"
# Get the base name without extension
base_name="${pcb%.kicad_pcb}"
sch_file="${base_name}.kicad_sch"
if [[ -f "$sch_file" ]]; then
echo " Found matching schematic: $sch_file"
# Both files exist, use project mode
kibot -c output.kibot.yaml -b "$pcb"
kibot -c jlcpcb.kibot.yaml -b "$pcb"
kibot -c pcbway.kibot.yaml -b "$pcb"
else
echo " No schematic found, using --no-check-sch"
# No schematic, skip the check
kibot -c output.kibot.yaml -b "$pcb" --no-check-sch
kibot -c jlcpcb.kibot.yaml -b "$pcb" --no-check-sch
kibot -c pcbway.kibot.yaml -b "$pcb" --no-check-sch
fi
fi
done
- apt-get update -y && apt-get install -y python3-reportlab
- python3 configs/gen-labels.py 'Fabrication/Labels/*.csv'
only:
refs:
- master
- alpha
# This matches maintenance branches
- /^(([0-9]+)\.)?([0-9]+)\.x/
# This matches pre-releases
- /^([0-9]+)\.([0-9]+)\.([0-9]+)(?:-([0-9A-Za-z-]+(?:\.[0-9A-Za-z-]+)*))?(?:\+[0-9A-Za-z-]+)?$/
artifacts:
when: always
paths:
- Fabrication/
- "*.kicad_pcb"
- "*.kicad_sch"
tags:
- docker
release:
stage: publish
image: node:24
only:
refs:
- master
- alpha
# This matches maintenance branches
- /^(([0-9]+)\.)?([0-9]+)\.x/
# This matches pre-releases
- /^([0-9]+)\.([0-9]+)\.([0-9]+)(?:-([0-9A-Za-z-]+(?:\.[0-9A-Za-z-]+)*))?(?:\+[0-9A-Za-z-]+)?$/
script:
- npm install @semantic-release/gitlab @semantic-release/exec @semantic-release/changelog @semantic-release/git -D
- npx semantic-release
tags:
- dockeroutput.kibot.yaml
kibot:
version: 1
globals:
resources_dir: configs
preflight:
update_xml: true
variants:
- name: rotated
comment: "Just a place holder for the rotation filter"
type: kibom
variant: rotated
pre_transform: _rot_footprint
outputs:
- name: ibom
comment: Interactive BOM
type: ibom
dir: Fabrication/ibom
options:
dark_mode: true
name_format: "index"
extra_fields: 'LCSC'
checkboxes: 'Placed'
- name: "SchPrint"
comment: "Print schematic PDF"
type: pdf_sch_print
dir: Fabrication/PDFs
options:
color_theme: dracula
background_color: true
- name: bom_labels
comment: "Print Labels"
type: bom
dir: Fabrication/Labels
options:
format: KICAD
group_fields: ['LCSC']
sort_style: ref
columns:
- field: LCSC
name: Part
- field: Value
- field: Footprint.releaserc.yml
---
plugins:
- "@semantic-release/commit-analyzer"
- - "@semantic-release/release-notes-generator"
- linkReferences: false
linkCompare: false
- - "@semantic-release/exec"
- verifyReleaseCmd: "echo ${nextRelease.version} > VERSION.txt"
- - "@semantic-release/changelog"
- changelogFile: CHANGELOG.md
- - "@semantic-release/git"
- assets:
- 'CHANGELOG.md'
- 'VERSION.txt'
- 'Fabrication/'
- '*.kicad_pcb'
- '*.kicad_sch'
message: "chore(release): ${nextRelease.version} [only cd]\n\n${nextRelease.notes}"
- "@semantic-release/gitlab"
branches:
- "master"
- "+([0-9])?(.{+([0-9]),x}).x"
- name: "alpha"
prerelease: "alpha"configs/gen-labels.py
#!/usr/bin/env python3
import csv
import sys
import os
import glob
from pathlib import Path
from reportlab.lib.pagesizes import mm
from reportlab.pdfgen import canvas
def csv_to_pdf_rows(csv_file, pdf_file):
# Custom page size: 20mm x 10mm
PAGE_WIDTH = 20 * mm
PAGE_HEIGHT = 10 * mm
c = canvas.Canvas(pdf_file, pagesize=(PAGE_WIDTH, PAGE_HEIGHT))
# Read CSV data
with open(csv_file, 'r') as f:
reader = csv.reader(f)
rows = list(reader)
if len(rows) < 3:
print(f"CSV file has only {len(rows)} rows, but we need at least 3 to skip first 2")
return
# Skip first 1 row: row 0 (empty) and row 1 (header line)
data_rows = rows[1:]
print(f"Processing {len(data_rows)} data rows (skipped first 2 rows)")
# Create one page per row
for row_index, row in enumerate(data_rows):
# Start new page (don't need c.showPage() for first page, but will add for consistency)
if row_index > 0:
c.showPage()
# Draw first column as header at top in larger font
if row: # Check if row has at least one column
first_cell = str(row[0])
if len(first_cell) > 25: # Allow longer text for header
first_cell = first_cell[:22] + "..."
c.setFont("Helvetica-Bold", 6) # Larger font for first column as header
c.drawString(2 * mm, PAGE_HEIGHT - 3 * mm, first_cell)
# Draw separator line
c.line(2 * mm, PAGE_HEIGHT - 4 * mm, PAGE_WIDTH - 2 * mm, PAGE_HEIGHT - 4 * mm)
# Draw remaining columns below in smaller font
c.setFont("Helvetica-Bold", 4) # Smaller font for other columns
y_position = PAGE_HEIGHT - 6 * mm # Start below separator
# Start from column 1 (second column)
for col_index in range(1, min(3, len(row))): # Limit to 2 more columns
cell = row[col_index]
text = str(cell)
if len(text) > 25:
text = text[:22] + "..."
c.drawString(2 * mm, y_position, text)
y_position -= 1.5 * mm
if y_position < 1 * mm:
break
c.save()
print(f"PDF saved as {pdf_file} with {len(data_rows)} pages (one per data row)")
def process_csv_files(input_pattern):
"""Process CSV files matching the input pattern"""
# Expand the pattern to get all matching files
csv_files = glob.glob(input_pattern)
if not csv_files:
print(f"No CSV files found matching pattern: {input_pattern}")
return
print(f"Found {len(csv_files)} CSV file(s) to process:")
for csv_file in csv_files:
# Create output filename: same directory, same base name, .pdf extension
input_path = Path(csv_file)
pdf_file = input_path.with_suffix('.pdf')
print(f"\nProcessing: {csv_file}")
print(f"Output will be: {pdf_file}")
try:
csv_to_pdf_rows(csv_file, str(pdf_file))
print(f"✓ Successfully created {pdf_file}")
except Exception as e:
print(f"✗ Error processing {csv_file}: {e}")
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python3 gen-labels.py <input_pattern>")
print("Examples:")
print(" python3 gen-labels.py Fabrication/Labels/*.csv")
print(" python3 gen-labels.py data.csv")
print(" python3 gen-labels.py *.csv")
print(" python3 gen-labels.py path/to/files/*.csv")
sys.exit(1)
input_pattern = sys.argv[1]
process_csv_files(input_pattern)